在一项突破性的发展中,Meta 推出了 ImageBind,这是一种创新的人工智能模型,在从多种模式进行整体学习方面弥合了机器和人类之间的差距。与依赖于每种模态的特定嵌入的传统 AI 系统不同,ImageBind 创建了一个共享的表示空间,使机器能够同时从文本、图像/视频、音频、深度、热和惯性测量单元 (IMU) 中学习。本文探讨了 ImageBind 的巨大潜力及其对人工智能未来的影响。
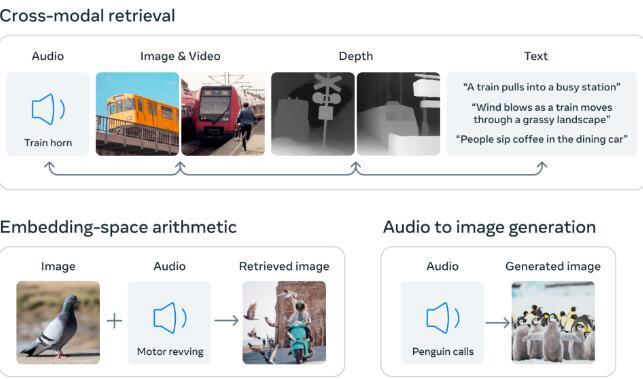
ImageBind 包含多种感官输入来生成媒体
ImageBind代表了AI功能的重大飞跃,超越了以前在单个模态上训练的专业模型的局限性。通过结合多个感官输入,ImageBind 为机器提供了将信息的各个方面连接在一起的全面理解。例如,Meta的Make-A-Scene可以利用ImageBind生成基于音频的图像,从而创建身临其境的体验,例如热带雨林或繁华的市场。此外,ImageBind 为更准确的内容识别、审核和创意设计打开了大门,包括无缝媒体生成和增强的多模式搜索功能。
作为 Meta 开发多模态 AI 系统的更广泛努力的一部分,ImageBind 为研究人员探索新领域奠定了基础。该模型结合3D和IMU传感器的能力可以彻底改变沉浸式虚拟世界的设计和体验。此外,ImageBind 通过支持跨各种形式(如文本、音频、图像和视频)的搜索,为探索记忆提供了丰富的途径。
长期以来,为多种模态创建联合嵌入空间一直是人工智能研究面临的挑战。ImageBind通过利用大规模视觉语言模型和利用与图像的自然配对来规避这个问题。通过对齐与图像共存的模态,ImageBind 无缝连接各种形式的数据。该模型展示了从整体上解释内容的潜力,使各种模式能够互动并建立有意义的联系,而无需事先接受联合培训。
ImageBind独特的缩放行为表明,随着更大的视觉模型,其性能会得到改善。通过自我监督学习和利用最少的训练示例,该模型展示了新功能,例如关联音频和文本或从图像预测深度。此外,ImageBind在音频和深度分类任务中优于以前的方法,实现了显着的准确性提升,甚至超过了仅根据这些模式训练的专用模型。
借助 ImageBind,Meta 为机器从各种模式中学习铺平了道路,推动 AI 进入了整体理解和多模态分析的新时代。该公司在人工智能领域取得了重大进展,该公司在一段时间前推出了自己的人工智能模型。



















