任意进任意出新的模块化人工智能模型
洛桑联邦理工学院的研究人员开发了一种新的、独特的模块化机器学习模型,用于灵活的决策。它能够输入任何模式的文本、视频、图像、声音和时间序列,然后输出任意数量或组合的预测。
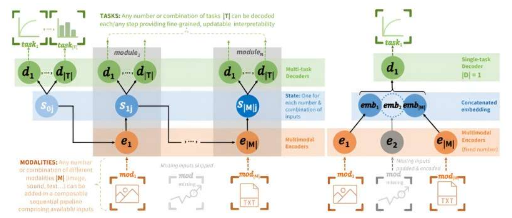
我们都听说过大型语言模型(LLM)——在大量文本上训练的大规模深度学习模型,构成了OpenAI的ChatGPT等聊天机器人的基础。下一代多模态模型(MM)可以从文本以外的输入中学习,包括视频、图像和声音。
创建较小规模的MM模型提出了重大挑战,包括对非随机缺失信息的鲁棒性问题。这是模型所没有的信息,通常是由于资源可用性存在偏差。因此,确保模型在做出预测时不会学习有偏差的缺失模式至关重要。
MultiModN扭转了局面
针对这个问题,来自EPFL计算机与通信科学学院教育机器学习(ML4ED)和机器学习与优化(MLO)实验室的研究人员开发并测试了与大型语言模型完全相反的模型。
MultiModN由MLO和耶鲁大学医学院联合主办的智能全球健康技术实验室负责人Mary-AnneHartley教授和ML4ED负责人TanjaKäser教授牵头,是一种独特的模块化多模式模型。它最近在NeurIPS2023会议上发布,有关该技术的论文已发布在arXiv预印本服务器上。
与现有的多模态模型一样,MultiModN可以从文本、图像、视频和声音中学习。与现有的MM不同,它由任意数量的较小、独立且特定于输入的模块组成,可以根据可用信息进行选择,然后以任意数量、组合或类型的输入序列串在一起。然后它可以输出任意数量的预测或预测的组合。
“我们在十项现实世界任务中评估了MultiModN,包括医疗诊断支持、学业成绩预测和天气预报。通过这些实验,我们相信MultiModN是第一个本质上可解释、抗MNAR的多模态建模方法,”VinitraSwamy解释道,博士学位ML4ED和MLO的学生,也是该项目的联合第一作者。
第一个用例:医疗决策
MultiModN的第一个用例将是作为资源匮乏环境中医务人员的临床决策支持系统。在医疗保健领域,临床数据经常缺失,可能是由于资源限制(患者无力承担测试)或资源丰富(由于执行了更好的测试而导致测试冗余)。MultiModN能够从现实世界的数据中学习,而不采用其偏差,并根据任何输入组合或数量调整预测。
Hartley解释道:“缺失是资源匮乏环境中数据的一个标志,当模型学习这些缺失模式时,它们可能会将偏差编码到预测中。面对不可预测的可用资源时对灵活性的需求正是MultiModN的灵感所在。”也是一名医生。
从实验室到现实生活
然而,发布只是实施的第一步。Hartley一直与洛桑大学医院(CHUV)和伯尔尼大学医院Inselspital的同事合作,开展临床研究,重点关注资源匮乏环境下的肺炎和结核病诊断,他们正在南非、坦桑尼亚、纳米比亚和贝宁招募数千名患者。
研究团队开展了大规模的培训活动,教导100多名医生系统地收集图像和超声视频等多模态数据,以便训练MultiModN对来自资源匮乏地区的真实数据敏感。
CHUV的传染病医生NoémieBoillat-Blanco博士说:“我们正在收集MultiModN旨在处理的复杂多模态数据。”伯尔尼大学医院Inselspital的KristinaKeitel博士补充道:“我们很高兴看到一个模型能够认识到我们环境中资源缺失的复杂性以及常规临床评估系统性缺失的复杂性。”
MultiModN的开发和培训是EPFL努力的延续,旨在使机器学习工具适应现实并服务于公众利益。它是在Meditron推出后不久推出的,Meditron是世界上表现最好的开源法学硕士,也旨在帮助指导临床决策。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
在众多紧凑型性能车中,大众高尔夫GTI始终以其独特的驾驶乐趣和经典形象占据着重要地位。对于预算有限但又追求...浏览全文>>
-
2022款的大众蔚揽以其优雅的设计和出色的性能在市场上占据了一席之地。对于预算在20-30万元之间的消费者来说,...浏览全文>>
-
池州长安启源E07作为一款备受关注的新能源SUV,在市场上拥有较高的关注度。这款车型凭借其时尚的设计和丰富的...浏览全文>>
-
近年来,随着汽车市场的竞争愈发激烈,各大品牌纷纷推出优惠政策以吸引消费者。作为国内知名汽车品牌之一,蚌...浏览全文>>
-
菱势汽车的菱势电卡是一款新能源物流车,如果您想预约试驾这款车型,以下是可能的流程及注意事项:预约试驾流...浏览全文>>
-
奥迪e-tron GT是一款融合了豪华与科技的电动跑车,如果您对这款车型感兴趣并希望进行试驾体验,可以通过以下...浏览全文>>
-
试驾五菱扬光是一次非常有趣的体验。以下是从咨询到试驾的完整体验过程:咨询阶段1 信息获取:首先通过官方...浏览全文>>
-
在试驾丰田bZ3C时,享受4S店专业服务的关键在于提前做好准备,并充分利用4S店提供的各项资源。以下是一些具体...浏览全文>>
-
近年来,新能源汽车市场蓬勃发展,各大品牌纷纷推出全新车型以满足消费者需求。作为大众汽车旗下备受关注的新...浏览全文>>
-
作为一款备受关注的新能源车型,2022款亳州迈腾GTE在市场上的表现一直引人注目。近期,其最低落地价已降至18 ...浏览全文>>
- 蚌埠揽巡最新价格2024款走势,市场优惠力度持续加大
- 亳州迈腾GTE多少钱 2022款落地价走势,近一个月最低售价18.79万起,性价比凸显
- 安庆探影多少钱?价格解读
- 天津滨海高尔夫GTI最新价格2025款,各车型售价大公开,性价比爆棚
- 试驾奕泽IZOA,感受豪华与科技的完美融合
- 五菱E5试驾预约操作指南
- ARCFOX极狐极狐 阿尔法S6试驾有哪些途径
- 奔腾T55预约试驾有哪些途径
- 东风风度帕拉丁试驾,开启完美驾驭之旅
- 试驾腾势N7,一键搞定,开启豪华驾驶之旅
- 开沃D10多少钱?经销商报价及市场优惠情况
- 飞度新款价格2025款多少钱?如何挑选性价比高的车
- 东莞途锐 2025新款价格全解买车必看
- 试驾东风小康EC36 II的流程及注意事项
- 北京BJ30预约试驾预约流程
- 奥迪A6(进口)试驾预约,从咨询到试驾的完整体验
- 东风本田M-NV试驾全攻略
- 欧拉芭蕾猫落地价全解,买车必看的省钱秘籍
- 龙耀8L新车报价2022款,各配置车型售价全解析
- 沃尔沃S60新能源多少钱 2024款落地价实惠,配置丰富,不容错过