新技术提高了人工智能利用二维相机绘制三维空间的能力
研究人员开发出一种技术,让人工智能 (AI) 程序能够利用多个摄像头捕捉的二维图像更好地绘制三维空间。由于该技术在有限的计算资源下有效运行,因此有望改善自动驾驶汽车的导航。
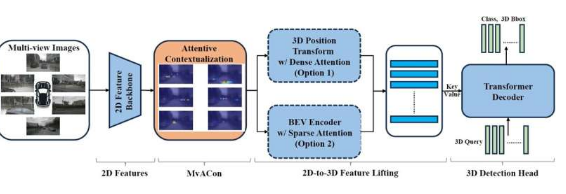
“大多数自动驾驶汽车都使用强大的人工智能程序,即视觉转换器,从多个摄像头拍摄二维图像,并创建车辆周围三维空间的表示,”该论文的通讯作者、北卡罗来纳州立大学电气与计算机工程副教授吴天福说。“然而,虽然这些人工智能程序都采用了不同的方法,但仍有很大的改进空间。
“我们的技术称为多视角注意力语境化 (MvACon),是一种即插即用的补充技术,可与这些现有的视觉转换器 AI 结合使用,以提高其绘制 3D 空间的能力,”吴说。“视觉转换器不会从其摄像头获取任何额外数据,它们只是能够更好地利用这些数据。”
MvACon 有效地通过修改一种名为 Patch-to-Cluster 注意力 (PaCa) 的方法发挥作用,这种方法是吴和他的合作者去年发布的。PaCa 允许 transformer AI 更高效、更有效地识别图像中的物体。
吴说:“这里的关键进步是将我们在 PaCa 中展示的技术应用于使用多台摄像机绘制 3D 空间的挑战。”
为了测试 MvACon 的性能,研究人员将其与三种领先的视觉转换器(BEVFormer、BEVFormer DFA3D 变体和 PETR)结合使用。在每种情况下,视觉转换器都会从六个不同的摄像头收集 2D 图像。在这三种情况下,MvACon 都显著提高了每个视觉转换器的性能。
“在定位物体以及物体的速度和方向方面,性能得到了特别的改善,”吴说。“而将 MvACon 添加到视觉转换器中所带来的计算需求的增加几乎可以忽略不计。”
“我们的下一步包括使用其他基准数据集测试 MvACon,以及使用来自自动驾驶汽车的实际视频输入进行测试。如果 MvACon 继续胜过现有的视觉转换器,我们乐观地认为它将被广泛采用。”
该论文“多视图注意语境化用于多视图 3D 物体检测”将于 6 月 20 日在华盛顿州西雅图举行的 IEEE/CVF 计算机视觉和模式识别会议上发表。
论文第一作者为北卡州立大学应届博士毕业生刘贤鹏,论文共同作者包括中佛罗里达大学的郑策、陈晨,蚂蚁集团的钱明、薛楠,以及OPPO美国研究中心的张哲斌、李晨。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
在众多紧凑型性能车中,大众高尔夫GTI始终以其独特的驾驶乐趣和经典形象占据着重要地位。对于预算有限但又追求...浏览全文>>
-
2022款的大众蔚揽以其优雅的设计和出色的性能在市场上占据了一席之地。对于预算在20-30万元之间的消费者来说,...浏览全文>>
-
池州长安启源E07作为一款备受关注的新能源SUV,在市场上拥有较高的关注度。这款车型凭借其时尚的设计和丰富的...浏览全文>>
-
近年来,随着汽车市场的竞争愈发激烈,各大品牌纷纷推出优惠政策以吸引消费者。作为国内知名汽车品牌之一,蚌...浏览全文>>
-
菱势汽车的菱势电卡是一款新能源物流车,如果您想预约试驾这款车型,以下是可能的流程及注意事项:预约试驾流...浏览全文>>
-
奥迪e-tron GT是一款融合了豪华与科技的电动跑车,如果您对这款车型感兴趣并希望进行试驾体验,可以通过以下...浏览全文>>
-
试驾五菱扬光是一次非常有趣的体验。以下是从咨询到试驾的完整体验过程:咨询阶段1 信息获取:首先通过官方...浏览全文>>
-
在试驾丰田bZ3C时,享受4S店专业服务的关键在于提前做好准备,并充分利用4S店提供的各项资源。以下是一些具体...浏览全文>>
-
近年来,新能源汽车市场蓬勃发展,各大品牌纷纷推出全新车型以满足消费者需求。作为大众汽车旗下备受关注的新...浏览全文>>
-
作为一款备受关注的新能源车型,2022款亳州迈腾GTE在市场上的表现一直引人注目。近期,其最低落地价已降至18 ...浏览全文>>
- 蚌埠揽巡最新价格2024款走势,市场优惠力度持续加大
- 亳州迈腾GTE多少钱 2022款落地价走势,近一个月最低售价18.79万起,性价比凸显
- 安庆探影多少钱?价格解读
- 天津滨海高尔夫GTI最新价格2025款,各车型售价大公开,性价比爆棚
- 试驾奕泽IZOA,感受豪华与科技的完美融合
- 五菱E5试驾预约操作指南
- ARCFOX极狐极狐 阿尔法S6试驾有哪些途径
- 奔腾T55预约试驾有哪些途径
- 东风风度帕拉丁试驾,开启完美驾驭之旅
- 试驾腾势N7,一键搞定,开启豪华驾驶之旅
- 开沃D10多少钱?经销商报价及市场优惠情况
- 飞度新款价格2025款多少钱?如何挑选性价比高的车
- 东莞途锐 2025新款价格全解买车必看
- 试驾东风小康EC36 II的流程及注意事项
- 北京BJ30预约试驾预约流程
- 奥迪A6(进口)试驾预约,从咨询到试驾的完整体验
- 东风本田M-NV试驾全攻略
- 欧拉芭蕾猫落地价全解,买车必看的省钱秘籍
- 龙耀8L新车报价2022款,各配置车型售价全解析
- 沃尔沃S60新能源多少钱 2024款落地价实惠,配置丰富,不容错过