您可能听说过,一张图片胜过千言万语,但是,如果大型语言模型 (LLM) 以前从未见过图像,它能获得该图片吗?
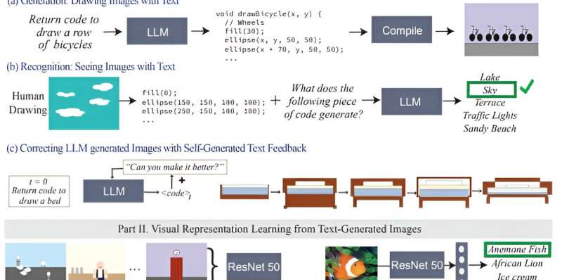
事实证明,纯文本训练的语言模型对视觉世界有着扎实的理解。他们可以编写图像渲染代码来生成具有有趣对象和构图的复杂场景——即使这些知识没有得到正确使用,LLM 也可以改进他们的图像。麻省理工学院计算机科学与人工智能实验室 (CSAIL) 的研究人员在提示语言模型针对不同图像自我纠正代码时观察到了这一点,其中系统通过每次查询改进了他们的简单剪贴画绘图。
这些语言模型的视觉知识来自于互联网上描述形状和颜色等概念的方式,无论是用语言还是代码。当给出“在丛林中画一只鹦鹉”这样的指示时,用户会慢跑 LLM 来思考之前在描述中读到的内容。
为了评估法学硕士拥有多少视觉知识,CSAIL 团队为法学硕士构建了一个“视力检查”:他们使用“视觉能力数据集”测试模型绘制、识别和自我纠正这些概念的能力。研究人员收集了这些插图的每一份最终草稿,训练了一个计算机视觉系统来识别真实照片的内容。
他们的研究成果发表在arXiv预印本服务器上。
“我们本质上是在不直接使用任何视觉数据的情况下训练视觉系统,”这项研究的共同主要作者、麻省理工学院电气工程与计算机科学 (EECS) CSAIL 博士后 Tamar Rott Shaham 说道。“我们的团队查询语言模型来编写图像渲染代码来为我们生成数据,然后训练视觉系统来评估自然图像。我们受到了视觉概念如何通过其他媒介(如文本)来表现的问题的启发。为了表达他们的视觉知识,法学硕士可以使用代码作为文本和视觉之间的共同点。”
为了构建这个数据集,研究人员首先查询模型以生成不同形状、物体和场景的代码。然后,他们编译该代码以渲染简单的数字插图,例如一排自行车,这表明 LLM 能够很好地理解空间关系,可以将两轮车画成水平行。另一个例子是,该模型生成了一个汽车形状的蛋糕,结合了两个随机概念。语言模型还产生了一个发光的灯泡,表明它能够创造视觉效果。
“我们的工作表明,当你查询 LLM(没有经过多模态预训练)来创建图像时,它知道的东西比看起来的多得多,”共同主要作者、EECS 博士生兼 CSAIL 成员 Pratyusha Sharma 说。“假设你要求它画一把椅子。该模型知道这件家具的其他信息,这些信息它可能不会立即呈现,因此用户可以查询该模型以改进它在每次迭代中产生的视觉效果。令人惊讶的是,该模型可以通过在很大程度上改进渲染代码来迭代丰富绘图。”
研究人员收集了这些插图,然后将其用于训练计算机视觉系统,该系统可以识别真实照片中的物体(尽管从未见过)。凭借这些合成的文本生成数据作为唯一参考点,该系统的表现优于其他使用真实照片训练的程序生成的图像数据集。
CSAIL 团队认为,将 LLM 的隐藏视觉知识与其他 AI 工具(如扩散模型)的艺术能力相结合也可能大有裨益。像 Midjourney 这样的系统有时缺乏持续调整图像中更精细细节的专业知识,这使得它们很难处理诸如减少图片中的汽车数量或将一个物体放在另一个物体后面之类的请求。如果 LLM 事先勾勒出扩散模型所要求的更改,那么最终的编辑可能会更令人满意。





